A abordagem de código aberto do OpenSeeker visa desmantelar o monopólio de dados para agentes de busca de IA
Com apenas 11.700 pontos de dados de treinamento e uma única execução de treinamento, o agente de busca de IA OpenSeeker alcança resultados que rivalizam com soluções da Alibaba e outros. Dados, código e modelo estão todos acessíveis abertamente.
Agentes de busca de IA poderosos—sistemas que buscam autonomamente informações na internet em múltiplas etapas—até agora foram território das grandes empresas de tecnologia. OpenAI, Google e Alibaba mantêm seus dados de treinamento trancados. Mesmo projetos que publicam seus pesos de modelo permanecem em silêncio sobre os dados por trás deles.
Esse monopólio de dados tem impedido a comunidade de pesquisa aberta por quase um ano, de acordo com pesquisadores da Universidade Jiao Tong de Xangai. Com o OpenSeeker, a equipe acadêmica pretende mudar isso: todos os dados de treinamento (licença MIT), o código, e os pesos do modelo estão abertamente disponíveis.
Estruturas de links da web substituem suposições de modelos de linguagem para dados de treinamento
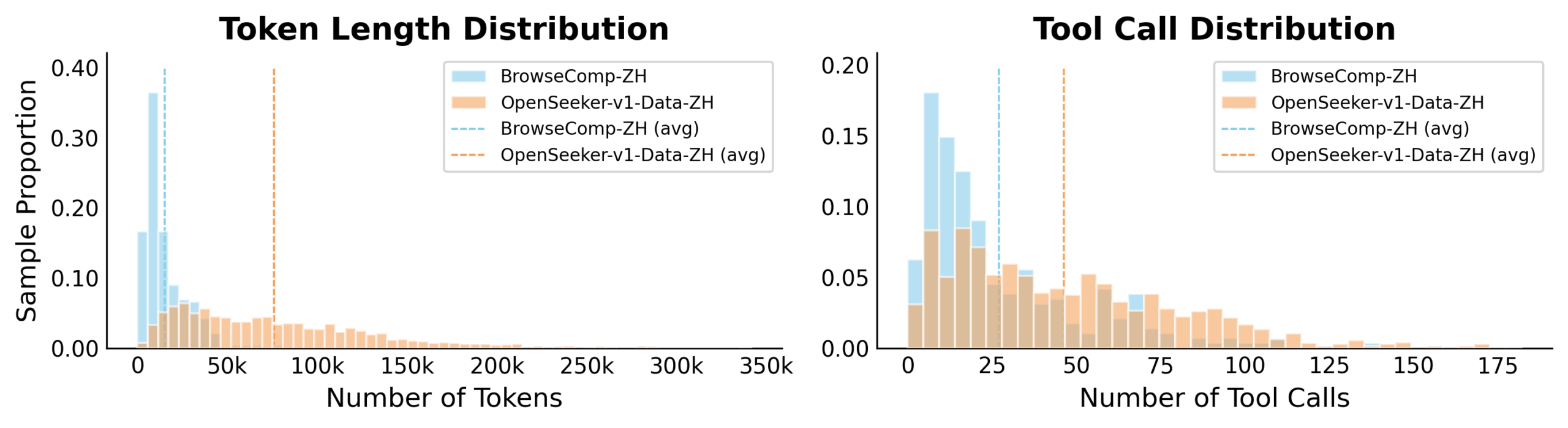
OpenSeeker se baseia em duas ideias principais para gerar dados. Para pares de perguntas e respostas, a equipe usa a estrutura de link real da web como sua base, gerando perguntas a partir dela. Começando a partir de páginas-semente selecionadas aleatoriamente dentro de um corpus da web (cerca de 68 GB de dados em inglês e 9 GB de dados em chinês), o sistema segue hyperlinks para páginas relacionadas e extrai as informações mais importantes.
Nomes e termos específicos são então trocados por descrições vagas, para que um agente de busca não consiga encontrar a resposta com uma simples busca por palavras-chave. Isso força uma busca e raciocínio genuínos em múltiplas etapas.

Um filtro em duas etapas elimina perguntas inutilizáveis: um modelo base forte não deve ser capaz de respondê-las sem ferramentas, mas deve ser capaz de resolvê-las com o contexto completo. Se qualquer condição falhar, a pergunta é descartada.
A segunda ideia foca nos caminhos de busca que o modelo aprende. Páginas da web contêm muito ruído que diminui a qualidade dos caminhos de solução registrados. Durante a geração de dados, um modelo professor recebe um resumo limpo dos resultados de busca anteriores e toma decisões melhores com base nisso.
Durante o treinamento, o modelo aluno vê os dados brutos, não limpos, mas ainda é esperado que reproduza as decisões de alta qualidade do professor. Isso o força a descobrir por conta própria como separar sinal de ruído.
11.700 pontos de dados versus 147.000: qualidade dos dados supera volume bruto
OpenSeeker é baseado no Qwen3-30B-A3B e foi treinado com apenas 11.700 pontos de dados em uma única execução usando ajuste fino supervisionado, sem qualquer aprendizado por reforço ou ajustes repetidos.
De acordo com o artigo, o modelo atingiu 48,4% no benchmark BrowseComp-ZH em língua chinesa, superando o Tongyi DeepResearch da Alibaba em 46,7%. O modelo da Alibaba passou por um processo de três etapas de pré-treinamento estendido, ajuste fino supervisionado e aprendizado por reforço.
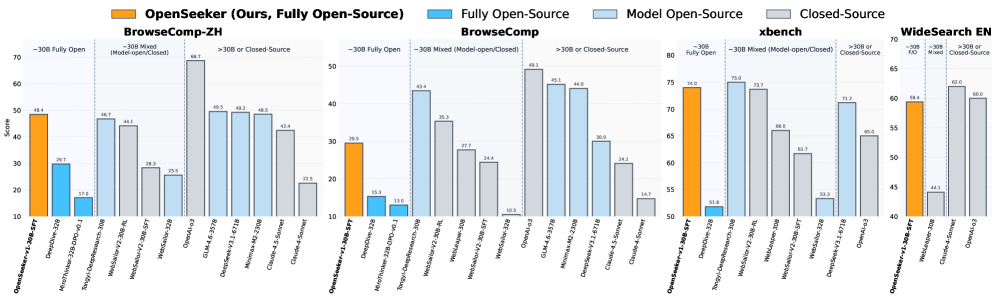
No BrowseComp em inglês da OpenAI, o OpenSeeker pontua 29,5% - quase o dobro dos 15,3% do DeepDive, o anterior líder entre os agentes totalmente abertos.
Uma comparação com o MiroThinker destaca o quanto a qualidade dos dados importa mais do que a quantidade bruta: aquele modelo foi alimentado com 147.000 exemplos de treinamento, mas só consegue 13,8% no BrowseComp-ZH. O OpenSeeker atinge 3,5 vezes essa pontuação com menos de um doze avos dos dados.
Ainda há uma lacuna em comparação com os sistemas proprietários mais fortes, no entanto. O GPT-5-High da OpenAI atinge 54,9% no BrowseComp, e o DeepSeek-V3.2 com 671 bilhões de parâmetros chega a 51,4%. O OpenSeeker opera com uma fração do tamanho do modelo e do esforço de treinamento.
A questão de quem tem acesso a dados de treinamento de alta qualidade tem sido um problema central na indústria de IA há algum tempo. No ano passado, uma equipe de pesquisa lançou o Common Pile, um conjunto de dados de texto de 8 TB construído a partir de fontes com licença aberta. Até agora, isso não fez muito para abalar a dominância dos modelos comerciais.
Notícias de IA Sem o Hype – Curado por Humanos
Como um assinante do THE DECODER, você obtém leitura sem anúncios, nosso boletim semanal de IA, o exclusivo Relatório de Fronteira "AI Radar" 6 vezes por ano, acesso a comentários e nosso arquivo completo.
Notícias de IA sem o hype
Curado por humanos.
- Mais de 16% de desconto.
- Leia sem distrações – sem anúncios do Google.
- Acesso a comentários e discussões da comunidade.
- Boletim semanal de IA.
- 6 vezes por ano: “AI Radar” – aprofundamentos em tópicos-chave de IA.
- Até 25% de desconto em eventos online do KI Pro.
- Acesso ao nosso arquivo completo de dez anos.
- Receba as últimas notícias de IA do The Decoder.