Perplexity torna públicos modelos de embedding que igualam Google e Alibaba a uma fração do custo de memória

Pontos Chave
- A Perplexity lançou dois modelos de embedding de código aberto, pplx-embed-v1 e pplx-embed-context-v1, projetados para converter consultas de busca e documentos em vetores numéricos para pré-selecionar sites relevantes em motores de busca impulsionados por IA.
- Os modelos utilizam compreensão de texto bidirecional, permitindo que considerem o contexto em ambas as direções dentro de uma frase, o que melhora a precisão de correspondência de consultas com conteúdo relevante.
- Eliminando a necessidade de descrições de tarefas pré-formatadas, os modelos visam abordar limitações chave de abordagens anteriores de embedding, oferecendo um processo de recuperação mais simplificado e eficaz.
O motor de busca de IA Perplexity está introduzindo dois novos modelos de embedding de texto projetados para igualar ou superar as ofertas do Google e da Alibaba a uma fração do custo de memória habitual. Ambos os modelos são de código aberto.
Antes que um modelo de linguagem possa responder a uma consulta de busca, ele precisa encontrar os documentos certos entre bilhões de páginas da web. Essa primeira etapa de filtragem é realizada por modelos de embedding, que traduzem consultas e documentos em vetores numéricos para que a similaridade semântica se torne algo que você pode calcular. A qualidade desses embeddings determina diretamente o que é passado para os modelos de classificação e, em última instância, para o modelo de linguagem que gera a resposta.
A Perplexity agora lançou dois modelos de embedding, pplx-embed-v1 e pplx-embed-context-v1. O primeiro lida com recuperação clássica de texto denso, enquanto o segundo também incorpora trechos no contexto de seu documento circundante; útil para desambiguar seções complicadas. Ambos vêm em versões de 0,6 bilhões e 4 bilhões de parâmetros.

A leitura bidirecional dá mais contexto aos embeddings
De acordo com os pesquisadores, a maioria dos modelos de embedding líderes é construída em modelos de linguagem que processam texto apenas da esquerda para a direita. Cada palavra só pode "ver" o que veio antes dela. Isso funciona bem para geração de texto, mas é um problema para entender o significado, uma vez que a intenção de uma frase muitas vezes depende do que vem depois.
A Perplexity começa com os modelos pré-treinados Qwen3 da Alibaba, que originalmente apenas liam da esquerda para a direita, e os modifica para ler em ambas as direções. O modelo é então treinado com um método de preenchimento de lacunas semelhante ao BERT do Google: palavras são aleatoriamente mascaradas em trechos de texto, e o modelo aprende a prever o que está faltando a partir do contexto circundante em ambas as direções. Os pesquisadores chamam isso de pré-treinamento de difusão.
O treinamento utilizou cerca de 250 bilhões de tokens em 30 idiomas: metade de sites educacionais em inglês no conjunto de dados FineWebEdu, metade cobrindo 29 outros idiomas do FineWeb2. Em estudos de ablação, a abordagem bidirecional apresentou uma melhoria de aproximadamente um ponto percentual nas tarefas de recuperação.
Há também uma vantagem prática: ao contrário dos modelos concorrentes, o pplx-embed não precisa de descrições de tarefas anexadas a cada entrada. A Perplexity afirma que esses prefixos podem, na verdade, prejudicar a qualidade da busca se não forem consistentes entre o tempo de indexação e o tempo de consulta.
A quantização reduz os requisitos de memória em até 32x
Armazenar vetores de embedding para bilhões de páginas da web se torna caro rapidamente. A abordagem padrão utiliza valores de ponto flutuante de 32 bits (FP32). A Perplexity, em vez disso, treina seus modelos desde o início para usar inteiros de 8 bits (INT8), reduzindo a memória em 4x sem perder desempenho.
Uma variante binária ainda mais compacta—apenas um bit por valor—reduz os requisitos em 32x. Com o modelo de 4B, a perda de qualidade é inferior a 1,6 pontos percentuais, uma vez que seu vetor de embedding de 2.560 dimensões retém mais informações do que o vetor de 1.024 dimensões do modelo menor, afirma a Perplexity.
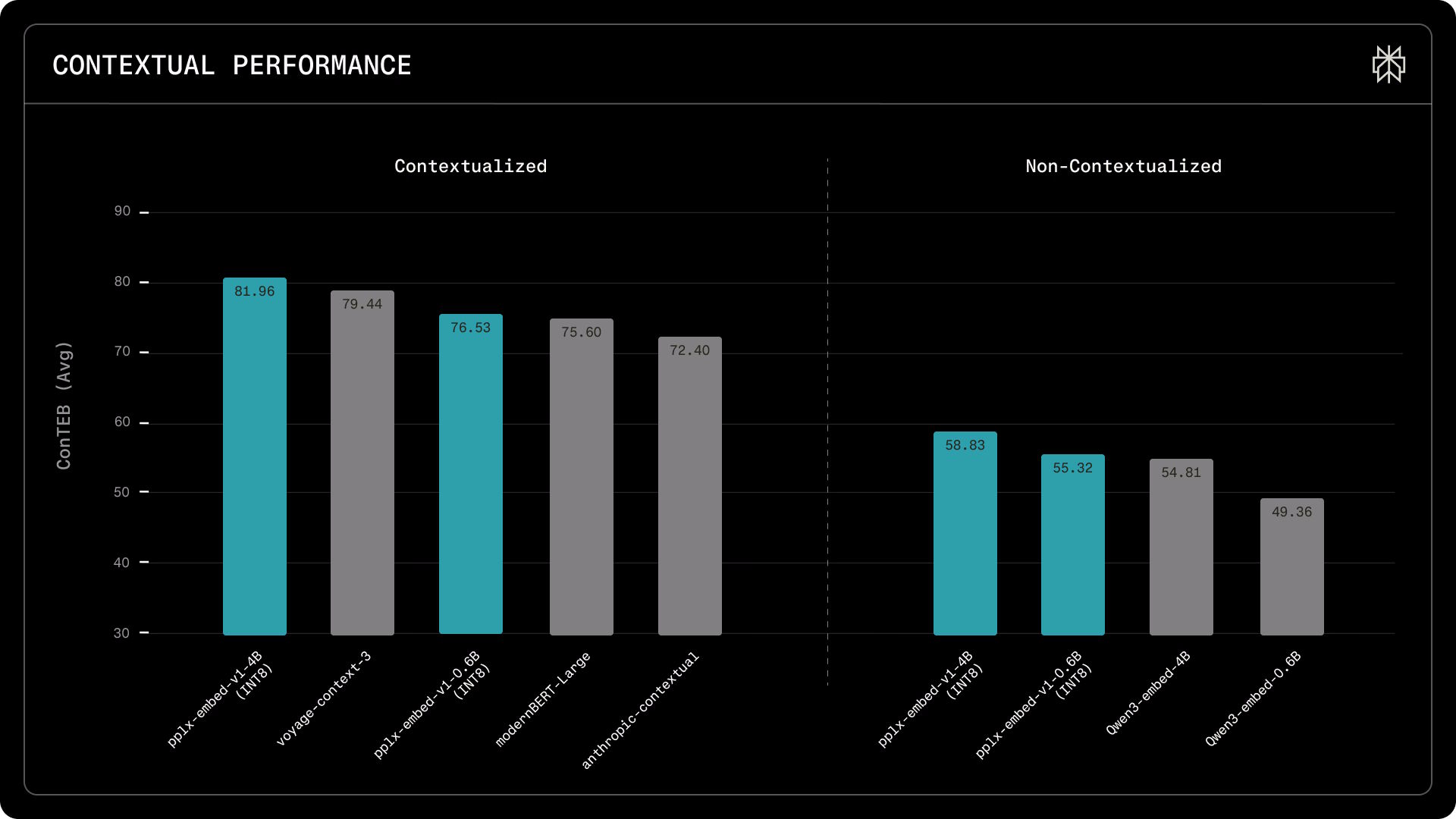
No benchmark de recuperação MTEB (Multilingual, v2), o pplx-embed-v1-4B pontua um nDCG@10 de 69,66 por cento - igualando o Qwen3-Embedding-4B (69,60 por cento) e superando o gemini-embedding-001 do Google (67,71 por cento), tudo isso enquanto usa significativamente menos memória. No benchmark de recuperação contextual ConTEB, o pplx-embed-context-v1-4B atinge 81,96 por cento, superando o modelo contextual do Voyage (79,45 por cento) e o modelo contextual da Anthropic (72,4 por cento).
No benchmark BERGEN, que mede o desempenho RAG de ponta a ponta desde a busca de documentos até a resposta gerada, o pequeno pplx-embed-v1-0.6B supera o muito maior Qwen3-embedding-4B em três das cinco tarefas. Isso o torna uma opção atraente onde latência e custos de computação são a prioridade.
Tráfego de busca real revela lacunas de desempenho mais amplas
A Perplexity afirma que benchmarks públicos refletem apenas parcialmente os desafios de busca do mundo real, uma vez que consultas incomuns, documentos ruidosos e mudanças de distribuição estão em grande parte ausentes. Portanto, a empresa construiu dois benchmarks internos usando até 115.000 consultas de busca reais contra mais de 30 milhões de documentos de mais de um bilhão de sites.
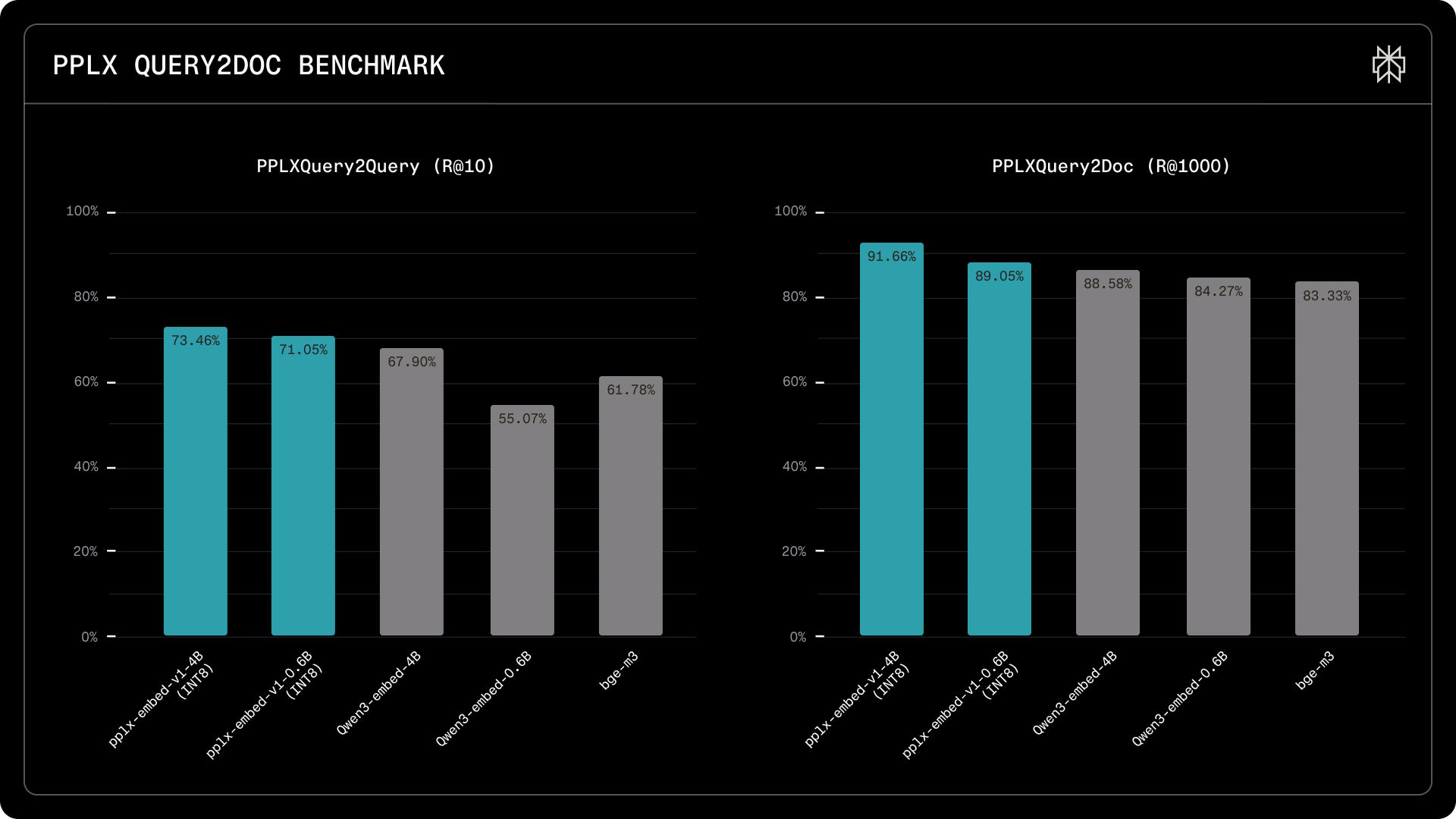
As lacunas aqui são mais pronunciadas. No benchmark PPLXQuery2Query, que testa se um modelo reconhece consultas com o mesmo significado, o pplx-embed-v1-4B encontra 73,5 por cento dos acertos relevantes nos dez primeiros resultados, contra 67,9 por cento do Qwen3-Embedding-4B. O modelo de 0,6B pontua 71,1 por cento, superando claramente o Qwen3-Embedding-0.6B (55,1 por cento) e o BGE-M3 (61,8 por cento). No teste PPLXQuery2Doc, que avalia a busca de documentos em 30 milhões

